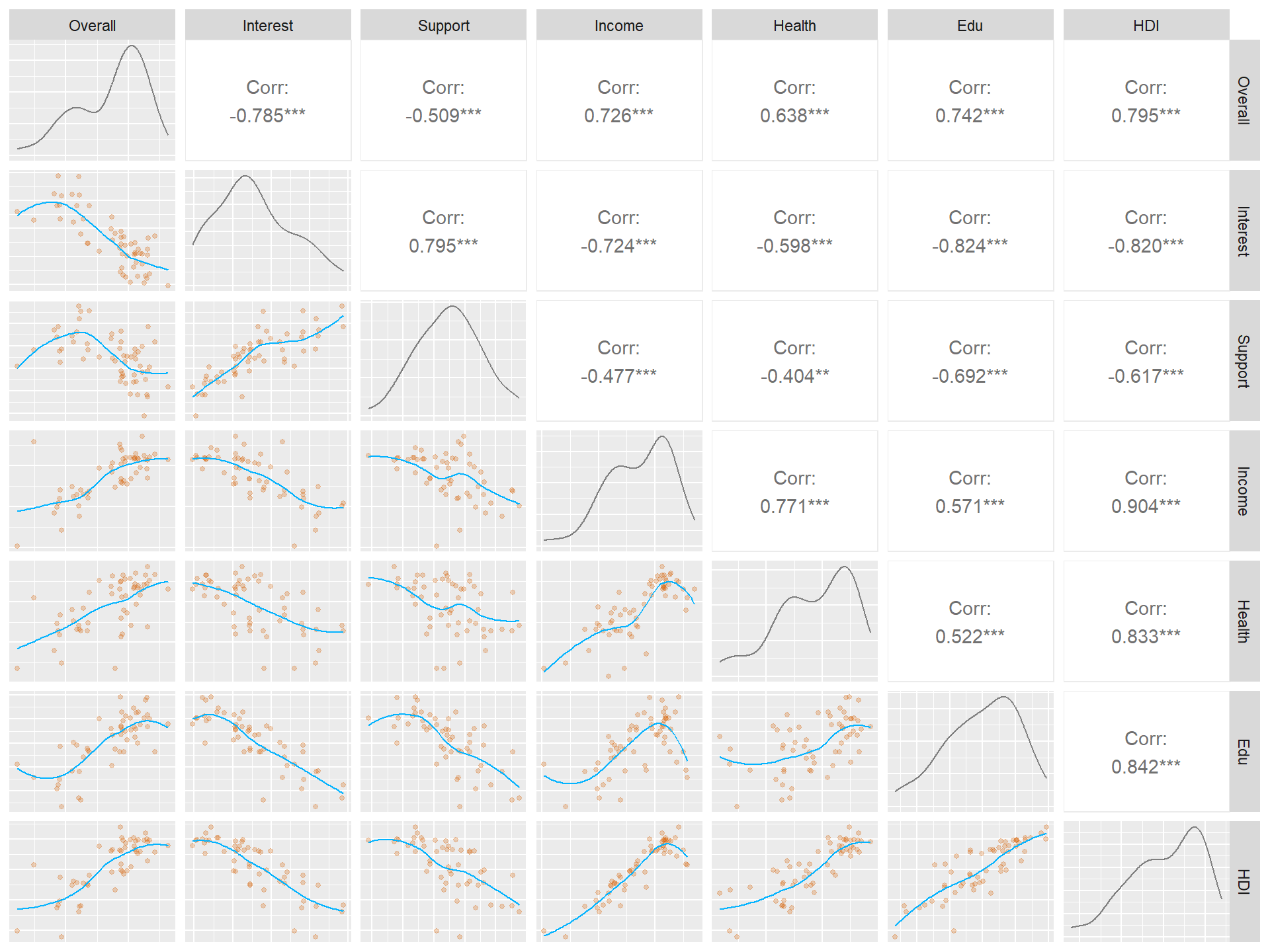
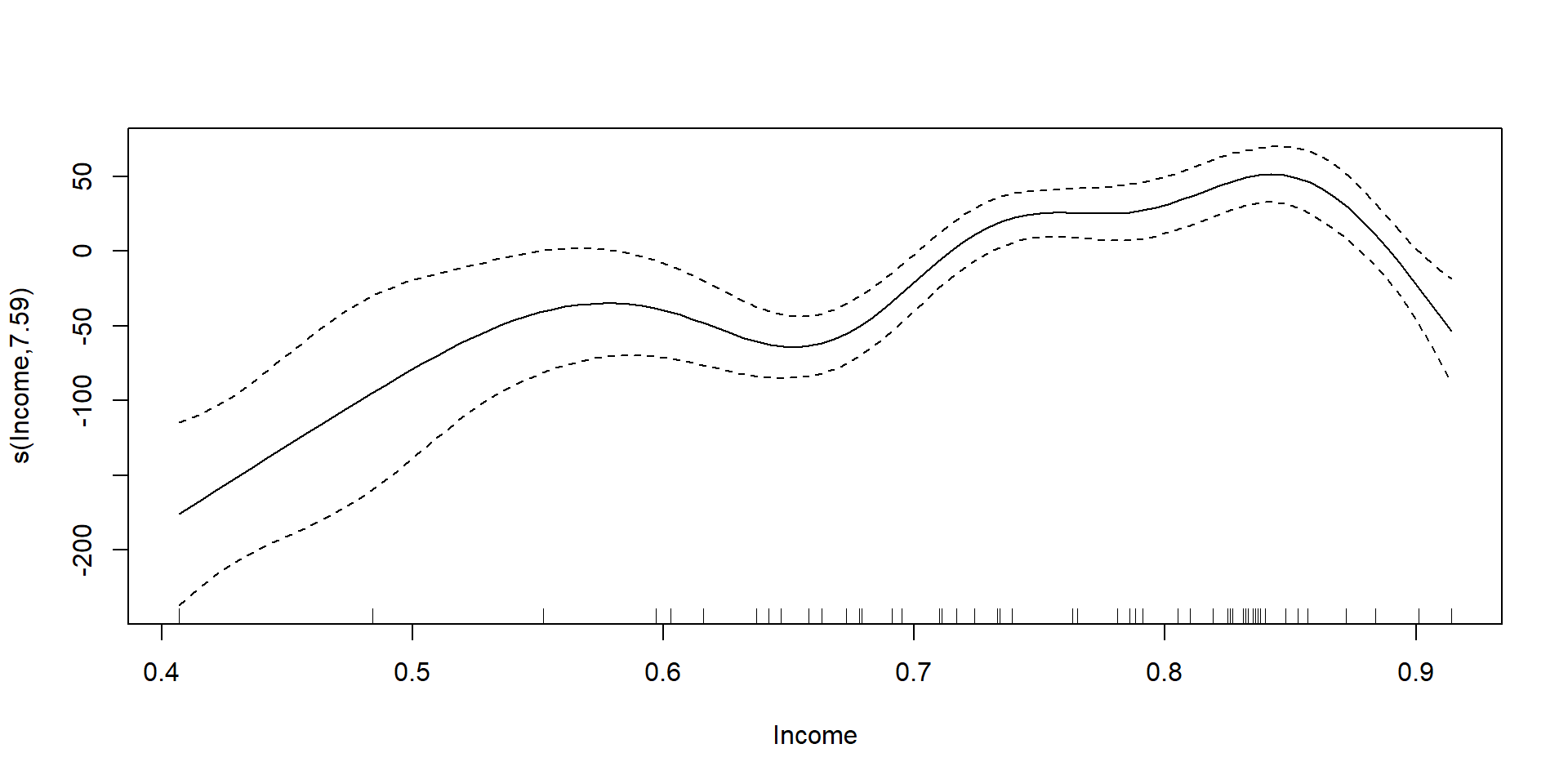
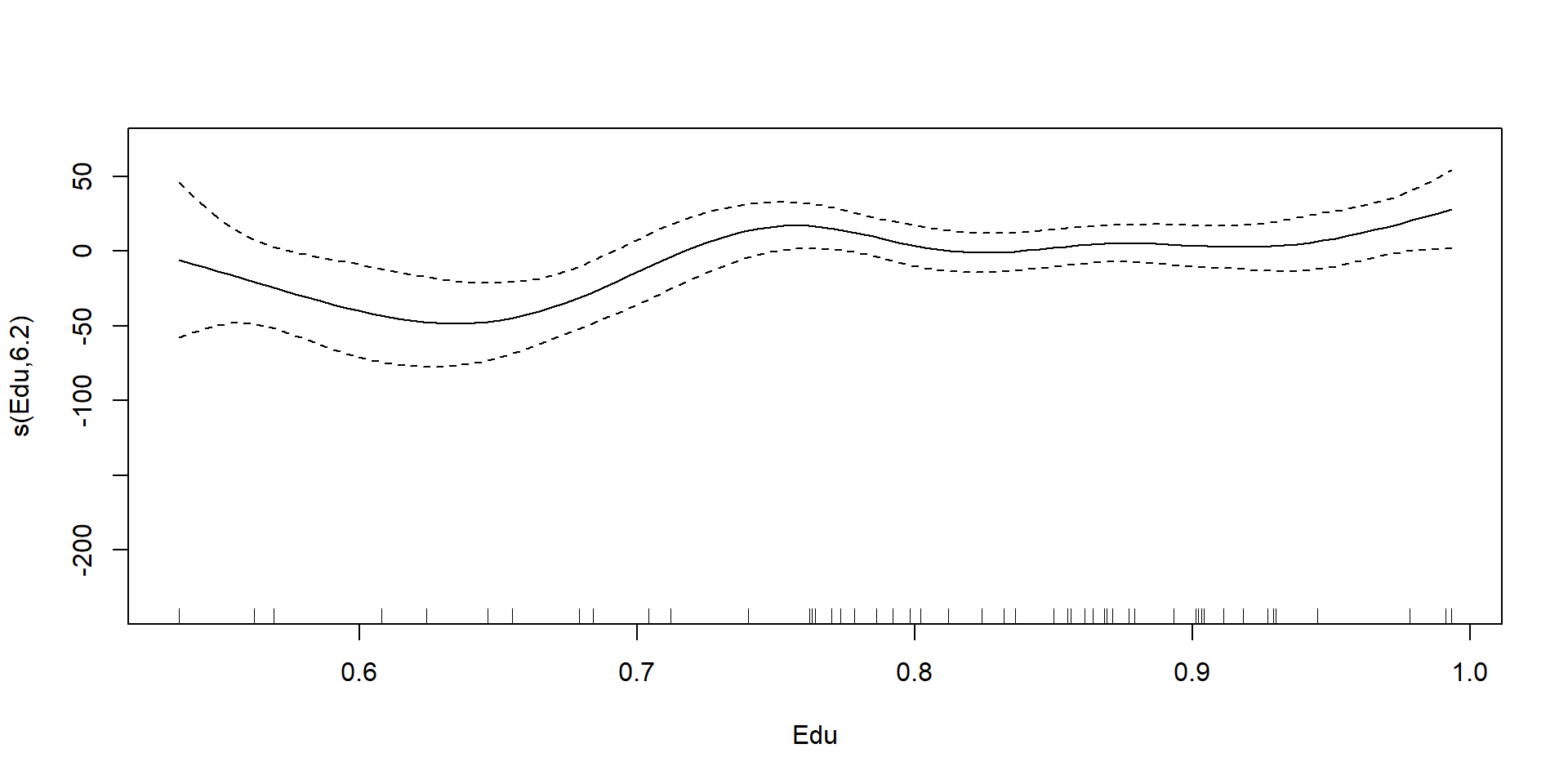
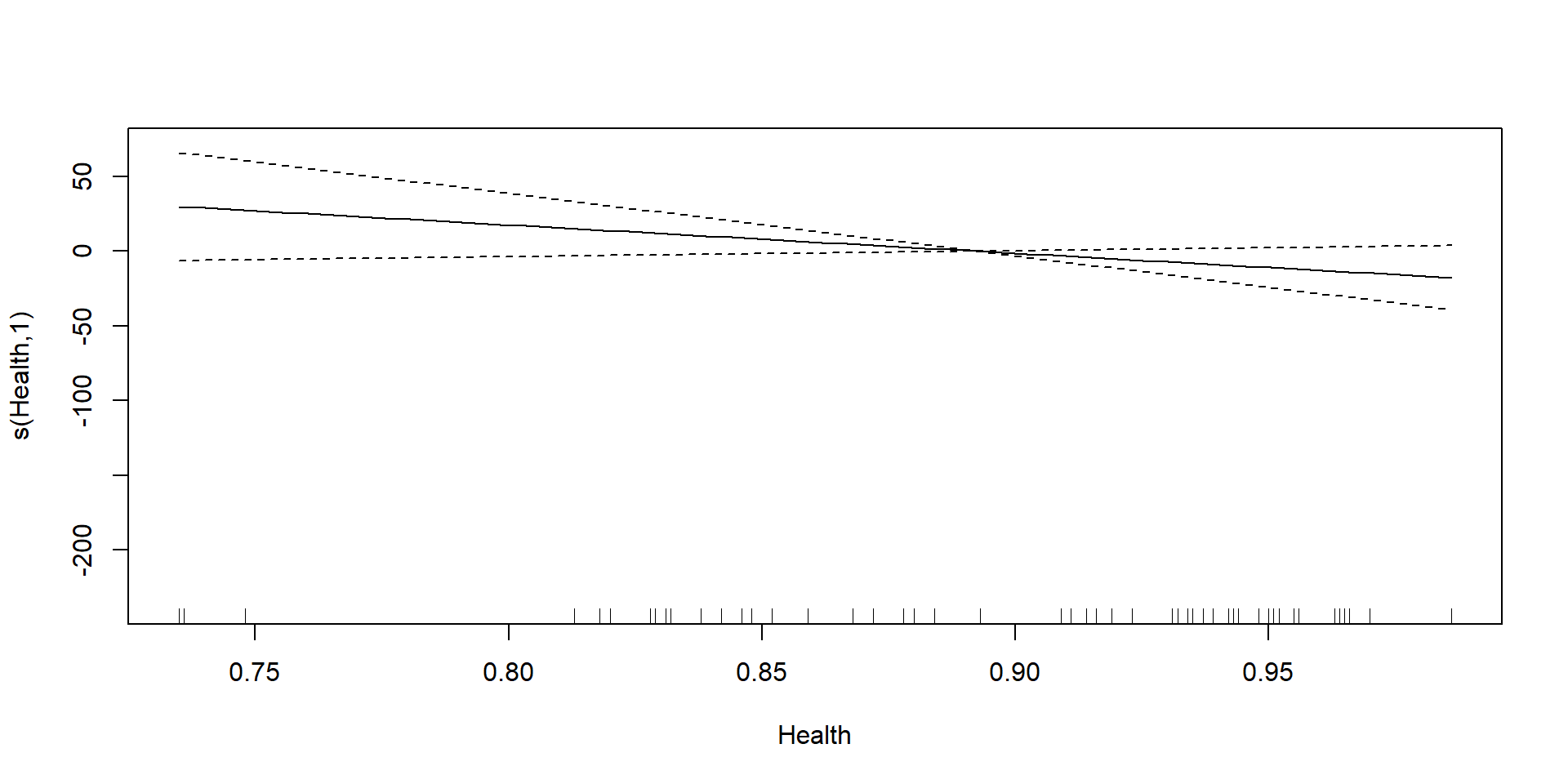
# https://raw.githubusercontent.com/m-clark/generalized-additive-models/master/data/pisasci2006.csv
pisa <- read.csv('data_raw_1/pisasci2006.csv')
pisa Country Overall Issues Explain Evidence Interest Support Income Health Edu HDI
1 Albania NA NA NA NA NA NA 0.599 0.886 0.716 0.724
2 Argentina 391 395 386 385 567 506 0.678 0.868 0.786 0.773
3 Australia 527 535 520 531 465 487 0.826 0.965 0.978 0.920
4 Austria 511 505 516 505 507 515 0.835 0.944 0.824 0.866
5 Azerbaijan 382 353 412 344 612 542 0.566 0.780 NA NA
6 Belgium 510 515 503 516 503 492 0.831 0.935 0.868 0.877
7 Brazil 390 398 390 378 592 519 0.637 0.818 0.646 0.695
8 Bulgaria 434 427 444 417 523 527 0.663 0.829 0.778 0.753
9 Canada 534 532 531 542 469 501 0.840 0.951 0.902 0.897
10 Chile 438 444 432 440 591 564 0.673 0.923 0.764 0.780
11 ChinaHK 542 528 549 542 536 529 0.853 0.966 0.763 0.857
12 Colombia 388 402 379 383 644 546 0.616 0.829 0.624 0.683
13 Croatia 493 494 492 490 535 514 0.724 0.878 0.762 0.785
14 Czech Republic 513 500 527 501 489 485 0.763 0.893 0.927 0.858
15 Denmark 496 493 501 489 463 483 0.838 0.914 0.911 0.887
16 Estonia 531 516 541 531 502 497 0.739 0.838 0.918 0.829
17 Finland 563 555 566 567 448 479 0.827 0.931 0.879 0.878
18 France 495 499 481 511 520 507 0.819 0.955 0.850 0.873
19 Germany 516 510 519 515 513 518 0.831 0.939 0.929 0.898
20 Greece 473 469 476 465 549 533 0.791 0.937 0.861 0.861
21 Hungary 504 483 518 497 522 512 0.733 0.842 0.855 0.808
22 Iceland 491 494 488 491 466 491 0.832 0.964 0.893 0.895
23 Indonesia 393 393 395 386 608 521 0.484 0.748 0.535 0.579
24 Ireland 508 516 505 506 481 484 0.837 0.932 0.945 0.904
25 Israel 454 457 443 460 509 512 0.786 0.952 0.901 0.877
26 Italy 475 474 480 467 529 511 0.810 0.963 0.832 0.866
27 Japan 531 522 527 544 512 468 0.825 0.986 0.869 0.891
28 Jordan 422 409 438 405 609 555 0.552 0.832 0.679 0.678
29 Kazakhstan NA NA NA NA NA NA 0.635 0.717 0.826 0.721
30 Korea 522 519 512 538 486 495 NA NA NA NA
31 Kyrgyz Republic 322 321 334 288 580 502 0.407 0.735 0.712 0.598
32 Latvia 490 489 486 491 504 494 0.711 0.820 0.855 0.793
33 Liechtenstein 522 522 516 535 504 524 0.941 0.931 NA NA
34 Lithuania 488 476 494 487 544 541 0.717 0.813 0.871 0.798
35 Luxembourg 486 483 483 492 515 522 0.901 0.931 0.764 0.863
36 Macao-China 511 490 520 512 524 521 NA NA NA NA
37 Mexico 410 421 406 402 611 536 0.695 0.880 0.684 0.748
38 Montenegro 412 401 417 407 561 529 0.647 0.852 0.802 0.762
39 Netherlands 525 533 522 526 452 447 0.848 0.942 0.903 0.897
40 New Zealand 530 536 522 537 461 470 0.781 0.943 0.991 0.901
41 Norway 487 489 495 473 472 485 0.884 0.948 0.993 0.940
42 Panama NA NA NA NA NA NA 0.646 0.872 0.735 0.745
43 Peru NA NA NA NA NA NA 0.591 0.832 0.688 0.697
44 Poland 498 483 506 494 501 513 0.710 0.872 0.812 0.795
45 Portugal 474 486 469 472 571 538 0.765 0.919 0.704 0.791
46 Qatar 349 352 356 324 565 520 0.914 0.909 0.655 0.816
47 Romania 418 409 426 407 591 540 0.658 0.831 0.792 0.757
48 Russian Federation 479 463 483 481 541 508 0.691 0.736 0.773 0.733
49 Serbia 436 431 441 425 523 520 0.642 0.848 0.770 0.749
50 Shanghai-China NA NA NA NA NA NA NA NA NA NA
51 Singapore NA NA NA NA NA NA 0.876 0.951 0.720 0.843
52 Slovak Republic 488 475 501 478 522 497 0.734 0.859 0.864 0.817
53 Slovenia 519 517 523 516 505 502 0.788 0.916 0.877 0.858
54 Spain 488 489 490 485 534 529 0.805 0.950 0.836 0.862
55 Sweden 503 499 510 496 454 471 0.836 0.956 0.904 0.898
56 Switzerland 512 515 508 519 504 510 0.857 0.970 0.856 0.893
57 Taiwan Province of China 532 509 545 532 533 546 NA NA NA NA
58 Thailand 421 413 420 423 642 569 0.603 0.842 0.569 0.661
59 Trinidad and Tobago NA NA NA NA NA NA 0.769 0.772 0.685 0.741
60 Tunisia 386 384 383 382 590 534 0.597 0.846 0.608 0.675
61 Turkey 424 427 423 417 540 563 0.679 0.828 0.562 0.681
62 United Arab Emirates NA NA NA NA NA NA 0.909 0.878 0.686 0.818
63 United Kingdom 515 514 517 514 464 470 0.833 0.934 0.798 0.853
64 United States 489 492 486 489 480 490 0.872 0.911 0.930 0.904
65 Uruguay 428 429 423 429 567 510 0.658 0.884 0.740 0.755